 Redisを使ったいろいろな autocomplete のアルゴリズムをメモ。
Redisを使ったいろいろな autocomplete のアルゴリズムをメモ。
trie(トライ木)
3つ目の @antirez アルゴリズムでは、登録後 bar に対して b, ba, bar というように各部分文字列だけをキーとして保存した。
これを拡張して、 b の次は a, ba の次は r というように接頭する文字列とその次に来る文字の対応関係を木構造で持つと、トライ木(trie)というデータ構造になる。
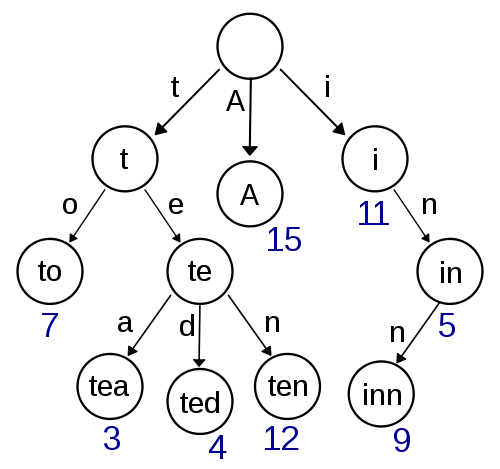
登録語が inn の場合
- root -> i
- i -> n
- in -> n
- inn -> + # 終端文字
というようになる。
検索の場合も同じようにルートから辿り、検索文字列を接頭語としてもつノードより下のノードを、終端文字にたどり着くまで辿る。
キーの追加
wikipedia の例を題材にする。
データ型は再び Sorted Set を利用。
候補となるキー(下の例では “tea” と “ten”)を ZADD で追加する。
> zadd trie: 0 t (integer) 0 > zadd trie:t 0 o (integer) 0 > zadd trie:to 0 + (integer) 0 > zadd trie:t 0 e (integer) 0 > zadd trie:te 0 a (integer) 0 > zadd trie:tea 0 + (integer) 0 > zadd trie:te 0 n (integer) 0 > zadd trie:ten 0 + ...
サジェスト
te で検索された場合、root -> t -> te とノードを辿り、このノードを起点に終端文字「+」が見つかるまでノードを辿る。
> zrange trie: 0 -1 1) "t" 2) "a" 3) "i" > zrange trie:t 0 -1 1) "e" 2) "o" > zrange trie:te 0 -1 1) "a" 2) "n" 3) "d" > zrange trie:tea 0 -1 1) "+" > zrange trie:ted 0 -1 1) "+" > zrange trie:ten 0 -1 1) "+"
以上から tea と ted と ten の3つが候補になる。
trie を使うと、サジェストする語をエレガントに retrieve できる。
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # vim: set fileencoding=utf8 | |
| ''' | |
| References | |
| - http://stackoverflow.com/a/1966188 | |
| - http://en.wikipedia.org/wiki/Tree_(data_structure) | |
| $ python suggest.py prefix | |
| ''' | |
| import sys | |
| import redis | |
| PREFIX = 'trie' | |
| TERMINAL = '+' | |
| r = redis.Redis(db=4) | |
| def add_word(word): | |
| key = PREFIX + ':' | |
| pipeline = r.pipeline(True) | |
| for c in word: | |
| r.zadd(key, c, ord(c)) | |
| key += c | |
| r.zadd(key, TERMINAL, 0) | |
| pipeline.execute() | |
| def suggest(text): | |
| for c in r.zrange(PREFIX + ":" + text, 0, -1): | |
| if c == TERMINAL: | |
| yield text | |
| else: | |
| for t in suggest(text + c): | |
| yield t | |
| if __name__ == '__main__': | |
| for word in suggest(sys.argv[1]): | |
| print word |
References
- StackOverflow : Redis autocomplete(2009/12/27)
http://stackoverflow.com/a/1966188

4 thoughts on “Redisでオートコンプリート(4)Trie”